---
title: "Variáveis instrumentais pt. 2"
subtitle: "Aula 8"
date: 2026-05-06
---
```{r}
#| include: false
library(tidyverse)
library(ivreg)
library(ggdag)
library(ggplot2)
```
## Anotações de aula
### Contexto: IV como estratégia auxiliar
Há contextos em que, mesmo fazendo experimentos, temos problemas como *spillover*. Nesse caso, podemos usar variáveis instrumentais de forma auxiliar. A variável instrumental por si só caiu em desuso, mas não caiu em desuso a inclusão das VI para melhorar a estimação dos efeitos causais de forma auxiliar.
Recapitulando o estimador IV e seus pressupostos:
$$
\hat{\beta}_{IV} = (Z^\top X)^{-1} Z^\top y
$$
| | |
|---|---|
| IV1 | Linearidade |
| IV2 | i.i.d. |
| IV3 | $Z^\top X$ é quadrada e inversível |
| IV4 | $X^\top\varepsilon \neq 0$ — modelo é endógeno |
| IV5 | $Z^\top\varepsilon = 0$ — instrumento é exógeno; restrição de exclusão |
| IV6 | $Z^\top X \neq 0$ — relevância |
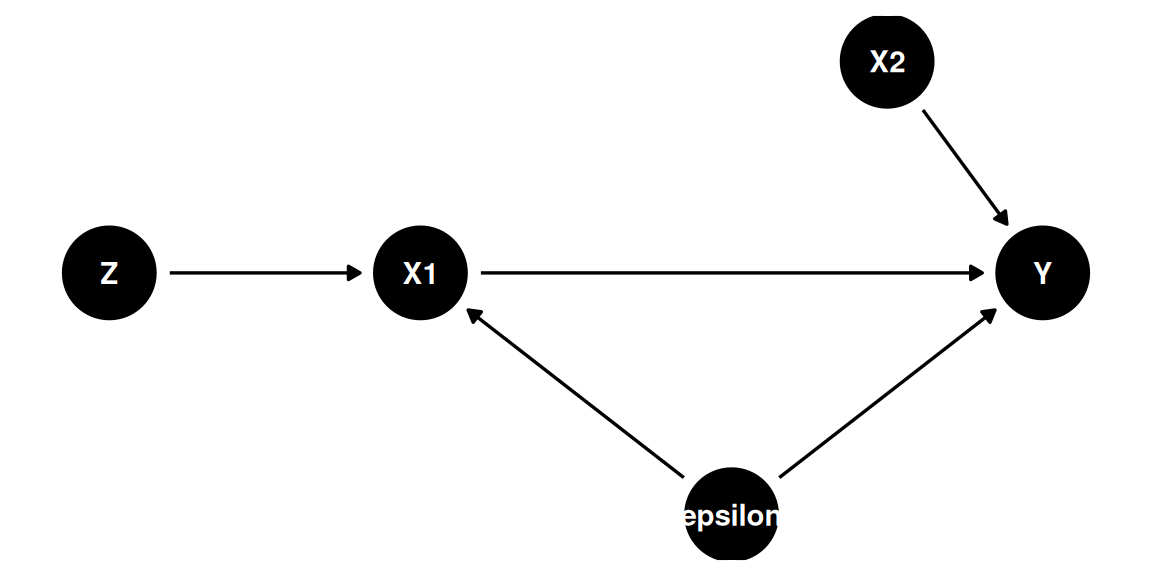
Considere um modelo com múltiplas variáveis onde apenas $X_1$ é endógena e $X_2$ é exógena, com instrumento $Z$ para $X_1$:
```{r}
#| message: false
#| fig-width: 6
#| fig-height: 3
dag_multi <- dagify(
X1 ~ Z + epsilon,
Y ~ X1 + X2 + epsilon,
latent = "epsilon",
coords = list(
x = c(Z = 0, X1 = 1, X2 = 2.5, Y = 3, epsilon = 2),
y = c(Z = 0, X1 = 0, X2 = 0.7, Y = 0, epsilon = -0.8)
)
)
ggdag(dag_multi) + theme_dag()
```
O PGD de $Y$ é $\beta_0 + \beta_1 X_1 + \beta_2 X_2 + \varepsilon$, mas a regressão OLS não produz o $\beta_1$ correto porque o modelo é endógeno ($X_1 \leftarrow \varepsilon$). Podemos resolver isso por VI.
### IV3 revisitado: regimes de identificação
Seja $L$ o número de colunas de $Z$ (instrumentos + variáveis exógenas) e $K$ o número de colunas de $X$ (variáveis que afetam $Y$). Como $Z_{n \times L}$ e $X_{n \times K}$, o produto $Z^\top X$ tem dimensão $L \times K$. A matriz só admite inversa quando $L = K$.
Isso não é apenas um requisito matemático, mas um requisito substantivo de inferência causal.
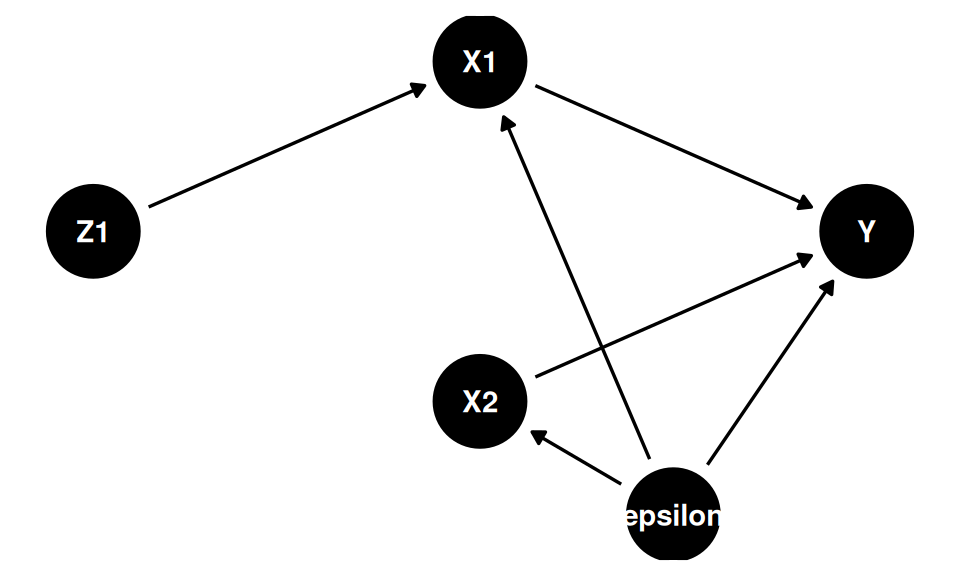
#### Sub-identificação ($L < K$)
Menos instrumentos do que variáveis endógenas — não é possível inverter $Z^\top X$. Exemplo: $X_1$ e $X_2$ ambas endógenas, mas há apenas um instrumento $Z_1$.
```{r}
#| message: false
#| fig-width: 5
#| fig-height: 3
dag_sub <- dagify(
X1 ~ Z1 + epsilon,
X2 ~ epsilon,
Y ~ X1 + X2 + epsilon,
latent = "epsilon",
coords = list(
x = c(Z1 = 0, X1 = 1, X2 = 1, Y = 2, epsilon = 1.5),
y = c(Z1 = 0, X1 = 0.6, X2 = -0.6, Y = 0, epsilon = -1)
)
)
ggdag(dag_sub) + theme_dag()
```
$$
Z = \begin{bmatrix} 1 & z_1 \end{bmatrix}_{n \times 2}
\qquad
X = \begin{bmatrix} 1 & X_1 & X_2 \end{bmatrix}_{n \times 3}
$$
$Z^\top X$ tem dimensão $2 \times 3$ — não é quadrada, portanto não é inversível.
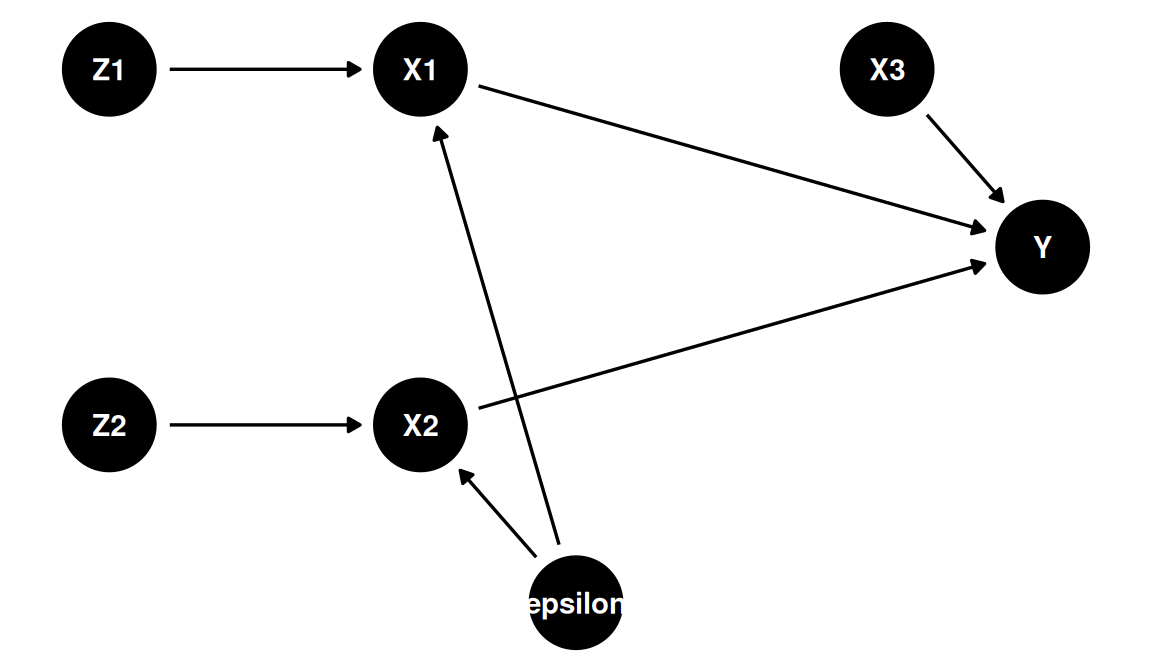
#### Justa-identificação ($L = K$)
Exatamente tantos instrumentos quanto variáveis endógenas. $Z^\top X$ é quadrada e inversível — o estimador IV pode ser aplicado diretamente.
```{r}
#| message: false
#| fig-width: 6
#| fig-height: 3.5
dag_just <- dagify(
X1 ~ Z1 + epsilon,
X2 ~ Z2 + epsilon,
Y ~ X1 + X2 + X3,
latent = "epsilon",
coords = list(
x = c(Z1 = 0, Z2 = 0, X1 = 1, X2 = 1, X3 = 2.5, Y = 3, epsilon = 1.5),
y = c(Z1 = 0.6, Z2 = -0.6, X1 = 0.6, X2 = -0.6, X3 = 0.6, Y = 0, epsilon = -1.2)
)
)
ggdag(dag_just) + theme_dag()
```
$$
Z = \begin{bmatrix} 1 & z_1 & z_2 & X_3 \end{bmatrix}_{n \times 4}
\qquad
X = \begin{bmatrix} 1 & X_1 & X_2 & X_3 \end{bmatrix}_{n \times 4}
$$
onde $Z$ contém o intercepto, os instrumentos e as variáveis exógenas; $X$ contém o intercepto, as variáveis endógenas e as variáveis exógenas.
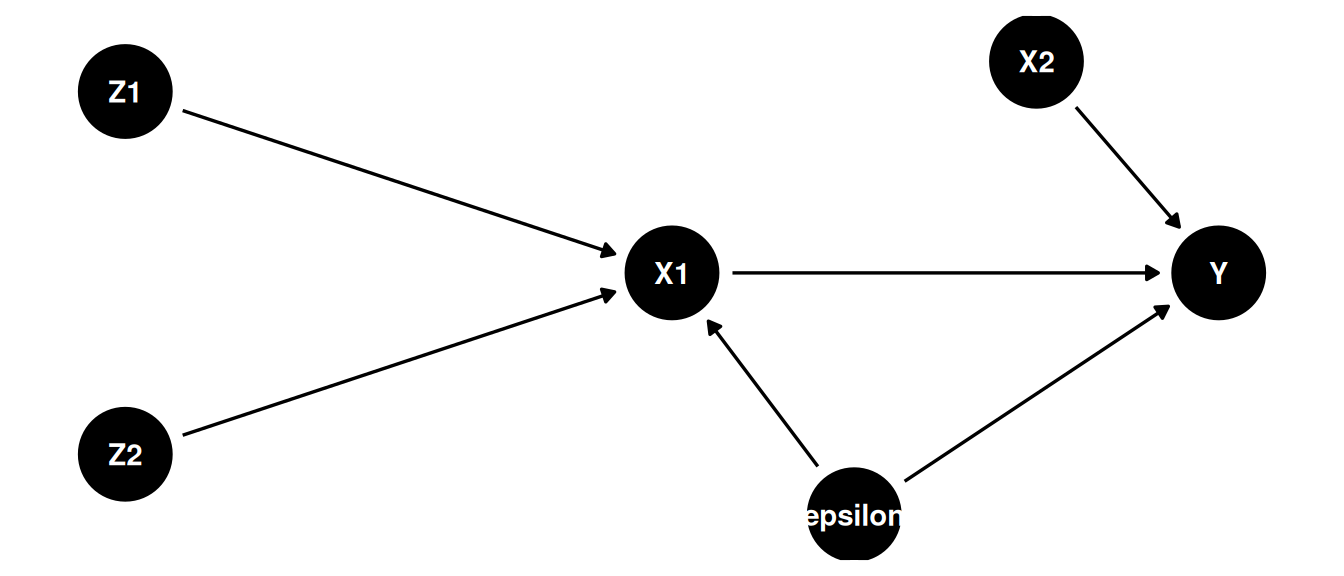
#### Sobre-identificação ($L > K$)
Mais instrumentos do que variáveis endógenas. Do ponto de vista informacional isso é melhor, mas as matemáticas não permitem usar o estimador IV diretamente ($Z^\top X$ não é quadrada). Precisamos do **2SLS**.
Exemplo: em @acemoglu2001colonial, mortalidade de colonos ($Z_1$) e relevo ($Z_2$) são usados como instrumentos para a qualidade das instituições ($X_1$), que afeta o crescimento econômico ($Y$).
```{r}
#| message: false
#| fig-width: 7
#| fig-height: 3
dag_over <- dagify(
X1 ~ Z1 + Z2 + epsilon,
Y ~ X1 + X2 + epsilon,
latent = "epsilon",
coords = list(
x = c(Z1 = 0, Z2 = 0, X1 = 1.5, X2 = 2.5, Y = 3, epsilon = 2),
y = c(Z1 = 0.6, Z2 = -0.6, X1 = 0, X2 = 0.7, Y = 0, epsilon = -0.8)
)
)
ggdag(dag_over) + theme_dag()
```
$$
Z = \begin{bmatrix} 1 & Z_1 & Z_2 & X_2 \end{bmatrix}_{n \times 4}
\qquad
X = \begin{bmatrix} 1 & X_1 & X_2 \end{bmatrix}_{n \times 3}
$$
$Z^\top X$ tem dimensão $4 \times 3$ — não é quadrada.
### Two-Stage Least Squares (2SLS)
Quando há mais de um instrumento (sobre-identificação), generalizamos a ideia de "usar apenas a variação exógena de $X$" via dois estágios:
**Passo 1 — Primeiro estágio:** regredir $X_1$ em todos os instrumentos e variáveis exógenas e calcular os valores preditos:
$$
X_1 = \alpha_0 + \alpha_1 Z_1 + \alpha_2 Z_2 + w
\qquad\Rightarrow\qquad
\hat{X}_1 = \hat{\alpha}_0 + \hat{\alpha}_1 Z_1 + \hat{\alpha}_2 Z_2
$$
**Passo 2 — Segundo estágio:** usar $\hat{X}_1$ no lugar de $X_1$:
$$
Y = \beta_0 + \beta_1 \hat{X}_1 + \beta_2 X_2 + \beta_3 X_3 + \varepsilon
\qquad\Rightarrow\qquad
\hat{\beta} = (\hat{X}^\top \hat{X})^{-1} \hat{X}^\top y
$$
onde $\hat{X}$ é a matriz com $\hat{X}_1$ no lugar de $X_1$ (as variáveis exógenas permanecem inalteradas).
#### Derivação do estimador 2SLS
Em notação matricial:
\begin{align*}
\hat{\alpha} &= (Z^\top Z)^{-1} Z^\top X \quad \text{[Passo 1]} \\
\hat{X} &= Z\hat{\alpha} \quad \text{[Passo 1.5 — valores preditos]} \\
\hat{\beta} &= (\hat{X}^\top \hat{X})^{-1} \hat{X}^\top y \quad \text{[Passo 2]}
\end{align*}
Substituindo $\hat{X} = Z\hat{\alpha}$ na equação de $\hat{\beta}$:
\begin{align*}
\hat{\beta} &= \left(\hat{\alpha}^\top Z^\top Z\, \hat{\alpha}\right)^{-1} \hat{\alpha}^\top Z^\top y
\end{align*}
E substituindo $\hat{\alpha} = (Z^\top Z)^{-1} Z^\top X$, usando $\hat{\alpha}^\top = X^\top Z(Z^\top Z)^{-1}$:
\begin{align*}
\hat{\beta} &= \left[X^\top Z(Z^\top Z)^{-1} \underbrace{Z^\top Z\,(Z^\top Z)^{-1}}_{=\,I} Z^\top X\right]^{-1} X^\top Z(Z^\top Z)^{-1} Z^\top y
\end{align*}
$$
\boxed{\hat{\beta}_{2SLS} = \left[X^\top Z(Z^\top Z)^{-1}Z^\top X\right]^{-1} X^\top Z(Z^\top Z)^{-1}Z^\top y}
$$
::: callout-note
O estimador 2SLS pode ser visto como uma **OLS ponderada**, onde $Z(Z^\top Z)^{-1}Z^\top$ é a matriz de pesos que dá peso zero à parte endógena de $X$ e peso maior à parte exógena.
Ao usar a fórmula fechada (ao invés de dois estágios manuais), evitamos a subestimação dos erros-padrão que ocorreria porque o segundo estágio manual usaria $\hat{X}$, não $X$, para calcular os resíduos.
:::
#### Demonstração em R
```{r}
set.seed(42)
n <- 10000
e <- rnorm(n, sd = 1)
dados <- tibble(
z1 = rnorm(n, mean = 2, sd = 2),
x = rnorm(n, mean = 10 + 2 * z1 - 5 * e, sd = 1),
y = rnorm(n, mean = 3 - 4 * x + 5 * e, sd = 1)
)
# β verdadeiro de x é -4
# Estratégia 1: razão de covariâncias (apenas uma var. endógena + um instrumento)
beta_cov <- with(dados, cov(z1, y) / cov(z1, x))
# Estratégia 2: estimador IV matricial — (Z'X)^{-1} Z'y (justa-identificação)
Z <- cbind(1, dados$z1)
X <- cbind(1, dados$x)
y <- dados$y
beta_iv <- solve(t(Z) %*% X) %*% t(Z) %*% y
# Estratégia 3: estimador 2SLS — fórmula fechada (generaliza para sobre-identificação)
beta_2sls <- solve(t(X) %*% Z %*% solve(t(Z) %*% Z) %*% t(Z) %*% X) %*%
(t(X) %*% Z %*% solve(t(Z) %*% Z) %*% t(Z) %*% y)
# No caso de justa-identificação, todas as fórmulas convergem
cat("Razão de covariâncias: ", round(beta_cov, 4), "\n")
cat("β_IV matricial [slope]: ", round(beta_iv[2], 4), "\n")
cat("β_2SLS [slope]: ", round(beta_2sls[2], 4), "\n")
```
Para uso em produção, o pacote `ivreg` implementa o 2SLS com erros-padrão corretos. A sintaxe `y ~ x | z` significa: regredir $y$ em $x$, usando $z$ como instrumento. Variáveis exógenas que não são instrumentadas aparecem dos dois lados do `|`.
```{r}
modelo_ols <- lm(y ~ x, data = dados)
modelo_iv <- ivreg(y ~ x | z1, data = dados)
summary(modelo_ols)
summary(modelo_iv)
```
O OLS, que ignora a endogeneidade, produz um coeficiente viesado. O estimador IV recupera o valor verdadeiro $\beta_1 = -4$.
### LATE: Local Average Treatment Effect
Variáveis instrumentais renderam vários Prêmios Nobel. Uma das contribuições mais belas é a de Angrist: a formalização do **LATE** (*Local Average Treatment Effect*).
Existem quatro tipos de pessoas no mundo:
| Tipo | Descrição |
|---|---|
| *Always takers* | Contrafactuais "fixos" — sempre fazem a mesma coisa em qualquer situação |
| *Never takers* | Idem — nunca mudariam de comportamento independente do instrumento |
| **Compliers** | Pessoas cujas vidas são efetivamente mudadas pela variável instrumental |
| *Defiers* | Fazem o oposto do instrumento (o pressuposto IV7 é exatamente "no defiers") |
O problema é que a VI estima o efeito causal **apenas para os compliers**. A variável instrumental não captura o efeito causal no abstrato — há pessoas que têm versões idênticas em qualquer contrafactual e que, portanto, não sofrem o efeito causal.
::: callout-note
Essa discussão é um dos usos mais interessantes da notação de inferência causal, pois torna explícita a heterogeneidade de efeitos que a VI é capaz de identificar.
:::
**Problema adicional:** a distribuição da população em cada um desses grupos depende do instrumento utilizado. Isso limita o **Teste de Sargan** — um teste de sobre-identificação que avalia a validade conjunta dos instrumentos.