flip <- sample(
c(0, 1),
size = 1000000,
replace=TRUE,
prob=c(0.5, 0.5)
)
prop.table(table(flip))flip
0 1
0.499789 0.500211 Real-world data, however, contain a nontrivial amount of noise, or irrelevant variation, which adds uncertainty to our conclusions.
According to the frequentist interpretation, probabilities represent proportions of specific events occurring over a large number of identical trials. Specifically, the probability of an event is the proportion of its occurence among infinitely many identical trials. (p. 162)
In contrast, according to the Bayesian interpretation, probabilities represent one’s subjective beliefs about the relative likelihood of events. For example, when we state that the probability of rain today is about 80%, we are not describing the frequency of rain events over multiple days. We are simply describing how certain we are about the event occurring. (p. 162)
There are three axioms of probability. Remarkably, we can derive the entire probability theory from these three basic rules.
- The first axiom states that the probability of an event \(A\) is non-negative. In mathematical notation, we can write this axiom as:
\[ P(A) \geq 0 \]
where \(P\) stands for “the probability of” and \(A\) represents the event.
This means that probabilities can be either zero or positive. For example, the probability of rolling a 3 cannot be negative.
- The second axiom states that the probability of the sample space is always \(1\). In mathematical notation:
\[ P(\Omega) = 1 \]
where \(\Omega\) represents the sample space, that is, the set of all possible outcomes produced by a trial.
[…]
The third axiom states that, if events \(A\) and \(B\) are mutually exclusive (that is, they cannot occur at the same time), then the probabilityt that either \(A\) or \(B\) occurs equals the probability that \(A\) occurs plus the probability that \(B\) occurs. In mathematical notation:
\[ P(A \text{ or } B) = P(A) + P(B) \]
For example, the probability that either rolling a number less than 3 or rolling a 3 equals the probability of rolling a number less than 3 plus the probability of rolling a 3, since the two are mutually exclusive events.
As soon as we assign a number to an event, we create what is known as a random variable. A random variable assigns a numeric value to each mutually exclusive event produced by a trial. (p. 165)
Each random variable has a probability distribution, which characterizes the likelihood of each value the variable can take. By definition, all probabilities in a distribution must add up to 1.
In mathematical notation, we can write the probability that the random variable \(X\) takes the value \(x\) as:
\[ P(X = x) = p \]
The Bernoulli distribution is the probability distribution of a binary variable. Since binary variables can take only two values (1 or 0), the Bernoulli distribution characterizes two probabilities: the probability that the variable equals 1 and the probability that the variable equals 0.
By definition, the sum of all probabilities in a Bernoulli distribution must equal 1. If we use \(p\) to denote the probability that the binary variable equals 1, the probability of the binary values equals 0 is \(1-p\) (notice that $p+(1-p) = 1). (p. 166)
flip <- sample(
c(0, 1),
size = 1000000,
replace=TRUE,
prob=c(0.5, 0.5)
)
prop.table(table(flip))flip
0 1
0.499789 0.500211 The normal distribution is a well-known symmetric, bell-shaped distribution, commonly used as an approximation for the distribution of many non-binary variables. (p. 169)
The normal distribution is the distribution of a normal random variable. It is characterized by two parameters: mean (\(\mu\)) and variance (\(\sigma^2\)). \(X \sim \mathcal{N}(\mu, sigma^2)\).
The probability density function of a normal probability distribution is determined by the following formula:
\[ \dfrac{1}{\sigma \sqrt{2 \pi}} e^{-\dfrac{(x - \mu)^2}{2 \sigma^2}} \]
The probability density funcion of the normal distribution provides the height of the density curve for each value of \(x\) that the random variable may take [any value on the real line, from \(-\infty\) to \(\infty\)].
A distribuição de uma variável aleatória que segue uma distribuição normal depende de dois parâmetros: a média e a variância, \(\mu\) e \(\sigma^2\), respectivamente. Se \(X\) segue uma distribuição normal, escrevemos \(X \sim \mathcal{N}(\mu, \sigma^2)\).
Vamos supor \(X \sim \mathcal{3, 4}\):
X <- rnorm(
1000000,
mean=3,
sd=2
)
hist(X, freq=FALSE)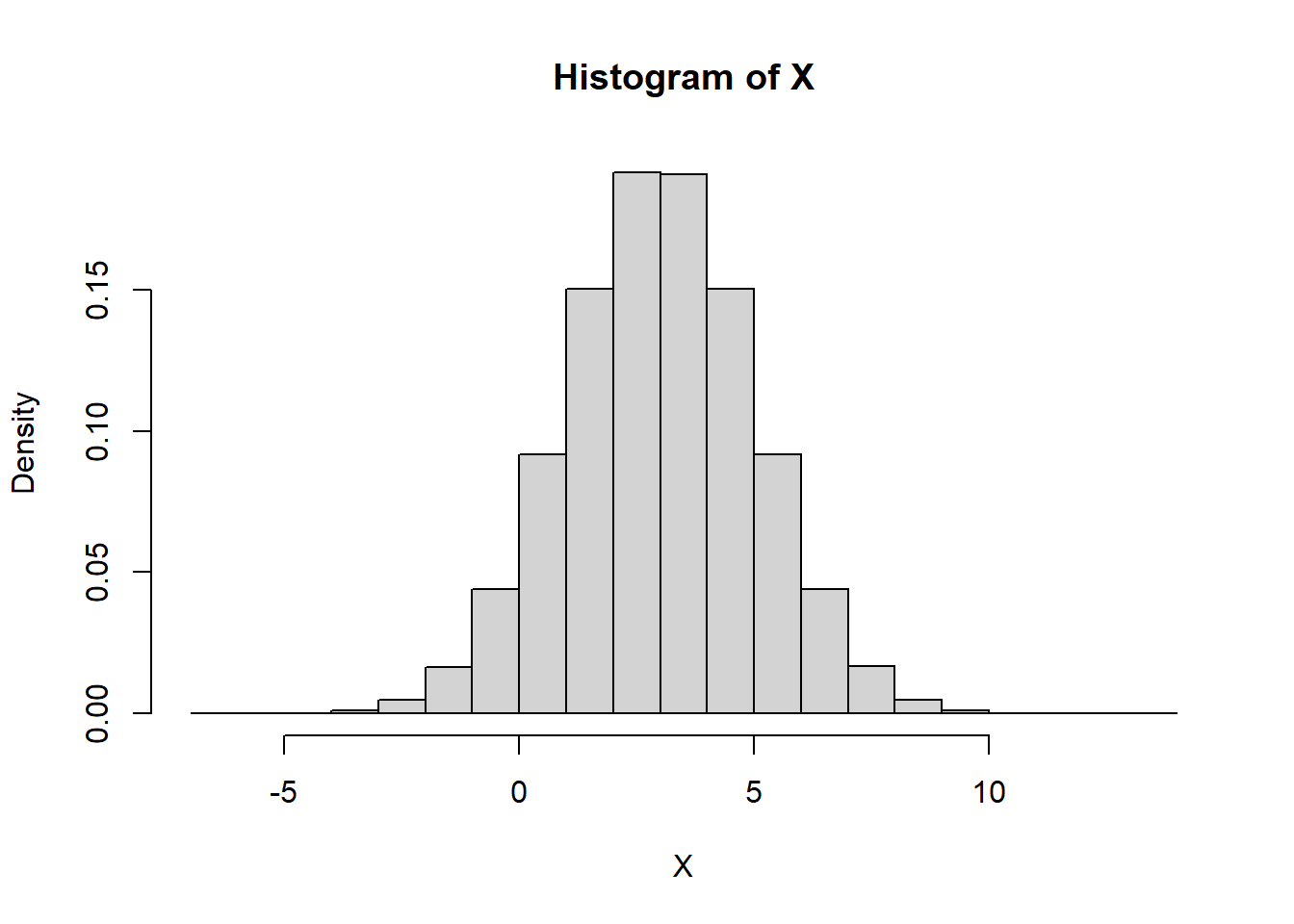
mean(X)[1] 2.99931var(X)[1] 3.996835How can we use a probability density function to compute probabilities? We can use the area underneath the curve of the probability density function to compute what are often referred to as cumulative probabilities, that is, the probability that a normal random variable takes a value within a given range. For example, the area under the curve between \(x_1\) and \(x_2\) equals the probability that the normal random variable takes a value between \(x_1\) and \(x_2\). (Since all probabilities in a distribution must add up to 1, the total area underneath the curve of a probability density function equals 1.)
The standard normal distribution is the normal distribution with mean 0 (\(\mu = 0\)) and variance 1 (\(\sigma^2 = 1\)).
\[ Z \sim \mathcal{0, 1} \]
The properties of the standard normal distribution are particularly useful. First, because the distribution is symmetric and centered at 0, the probability that Z takes a value less or equal to -z is the same as the probability that Z takes a value greater than or equal to z.
Second, in the standard normal distribution, about 95% of the observations are between -2 and 2, or more precisely, between -1.96 and 1.96. (p. 174)
To calculate probabilities of normal random variables, we can use the function
pnorm(), which stands for “the cumulative probability of a normal random variable from negative infinity to \(x\)”. By default, this function calculates the probability that the standard normal random variable takes a value less than or equal to the number specified inside the parantheses. For example, to calculate the probability that Z takes a value less than or equal to -1.96, we run:
pnorm(-1.96)[1] 0.0249979If we are interested in the probability that Z takes a value greater than or equal to a value, z, we can calculate the probability that Z takes a value less than or equal to z and compute 1 minus the resulting probability:
\[ P(X \geq x) = 1 - P(X \leq x) \]
1 - pnorm(1.96)[1] 0.0249979Now, if we are interested in the probability that Z takes a value between \(z_1\) and \(z_2\), we can calculate the probability that Z takes a value less than or equal to \(z_2\) minus the probability that Z takes a value less than or equal to \(z_1\).
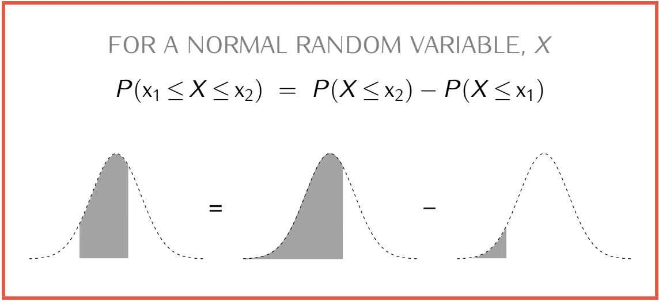
Suponha que queremos calcular a probabilidade de um número estar entre 1.96 e -1.96. Faríamos:
\[ P(-1.96 \leq Z \leq 1.96) = P(Z \leq 1.96) - P(Z \leq -1.96) \]
pnorm(1.96) - pnorm(-1.96)[1] 0.9500042Essas propriedades são fundamentais porque, na prática, podemos transformar qualquer variável aleatória normal em uma normal padrão a partir do seguinte:
\[ X \sim \mathcal{N}(\mu, \sigma^2), \dfrac{X - \mu}{\sigma} \sim \mathcal{N}(0, 1) \]
Z <- (X - 3) / 2
hist(Z, freq = FALSE)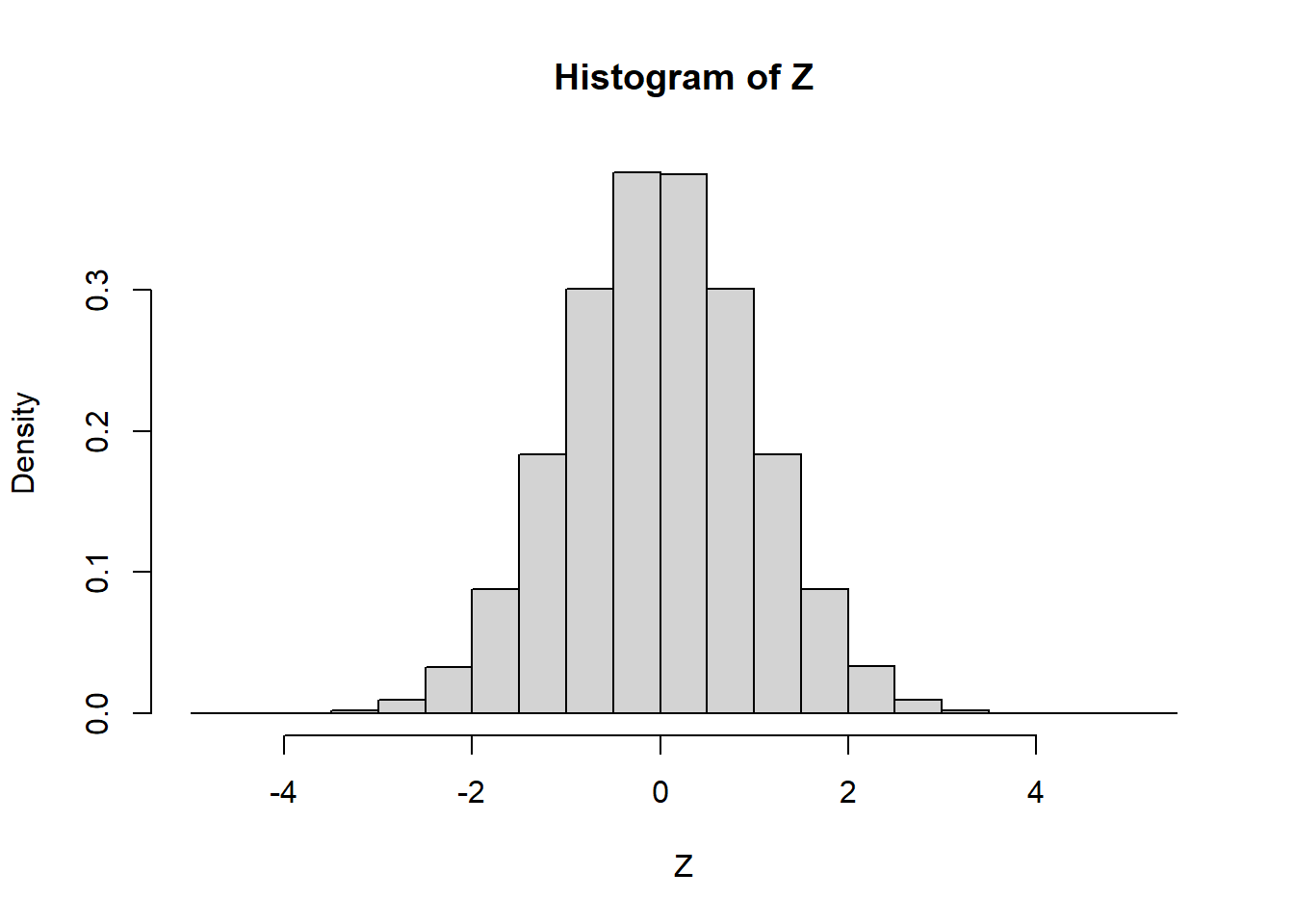
\[ \begin{align*} \mathbb{P}(-1.96 \leq Z \leq 1.96) &\approx 0.95 \\ \mathbb{P}(-1.96 \leq \frac{X-3}{2} \leq 1.96) &\approx 0.95 \\ \mathbb{P}(-0.92 \leq X \leq 6.92) &\approx 0.95 \end{align*} \]
To distinguish the sample statistics from the corresponding parameters at the population level, we use different terms to refer to them. The sample mean of \(X\), denoted as \(\bar{X}\), refers to the average value of \(X\) in a particular sample, while the expectation of X, denoted as \(\mathbb{E}(X)\), refers to the population mean of the random variable X. The sample variance of X, denoted as \(var(X)\), refers to the variance of X in a particular sample, while the population variance of X, denoted as \(\mathbb{V}(X)\), refers to the population variance of the random variable X. (p. 179-180)
The sample statistics differ from the population parameters because the sample contains noise. The noise comes from sampling variability. (p. 180)
The law of large numbers states that as the sample size increases, the sample mean of X approximates the population mean of X, also known as the expectation of X. (p 180)
\[ \text{as n increases, } \bar{X} = \dfrac{\sum_{i = 1}^n X_i}{n} \approx \mathbb{E}(X) \]
Vamos supor que conhecemos \(mathbb{E}(X)\) de uma variável aleatória \(X\), Bernoulli. Sendo \(mathbb{E}(X) = 0.6\), temos:
support_sample_1 <- sample(
c(1, 0),
size = 10,
replace = TRUE,
prob = c(0.6, 0.4)
)
support_sample_2 <- sample(
c(1, 0),
size = 1000,
replace = TRUE,
prob = c(0.6, 0.4)
)
support_sample_3 <- sample(
c(1, 0),
size = 1000000,
replace = TRUE,
prob = c(0.6, 0.4)
)
mean(support_sample_1)[1] 0.6mean(support_sample_2)[1] 0.593mean(support_sample_3)[1] 0.599241À medida que aumentamos o tamanho da amostra (o que nem sempre é viável, naturalmente), a estimativa da variável de interesse melhora. Em particular, chegamos cada vez mais perto do valor “verdadeiro” do parâmetro.
The central limit theorem states that as the sample size increases, the standardized sample mean of \(X\) can be approximated by the standard normal distribution. (p. 183)
\[ \text{as n increases, } \dfrac{\bar{X} - \mathbb{E}(X)}{\sqrt{\mathbb{V}(X) / n}} \sim \mathcal{N}(0, 1) \]
Propriedades do valor esperado:
Propriedades da variância:
Given those properties, one can prove that \(\mathbb{E}(\bar{X}) = \mathbb{E}(X)\) and that \(\mathbb{V}(\bar{X}) = \frac{\mathbb{V}(X)}{n}\).
Vamos supor um exemplo em que o suporte a um determinado candidato é de 60% (i.e., \(\mathbb{E}(\text{support}) = p = 0.6\) e \(\mathbb{V}(\text{support}) = p(1-p) = 0.24\)).
sd_sample_means <- c()
for (i in 1:10000){
support_sample <- sample(
c(1, 0),
size = 1000,
replace = TRUE,
prob = c(0.6, 0.4)
)
sd_sample_means[i] <- (mean(support_sample) - 0.6) / sqrt(0.24 / 1000)
}
hist(sd_sample_means, freq=FALSE)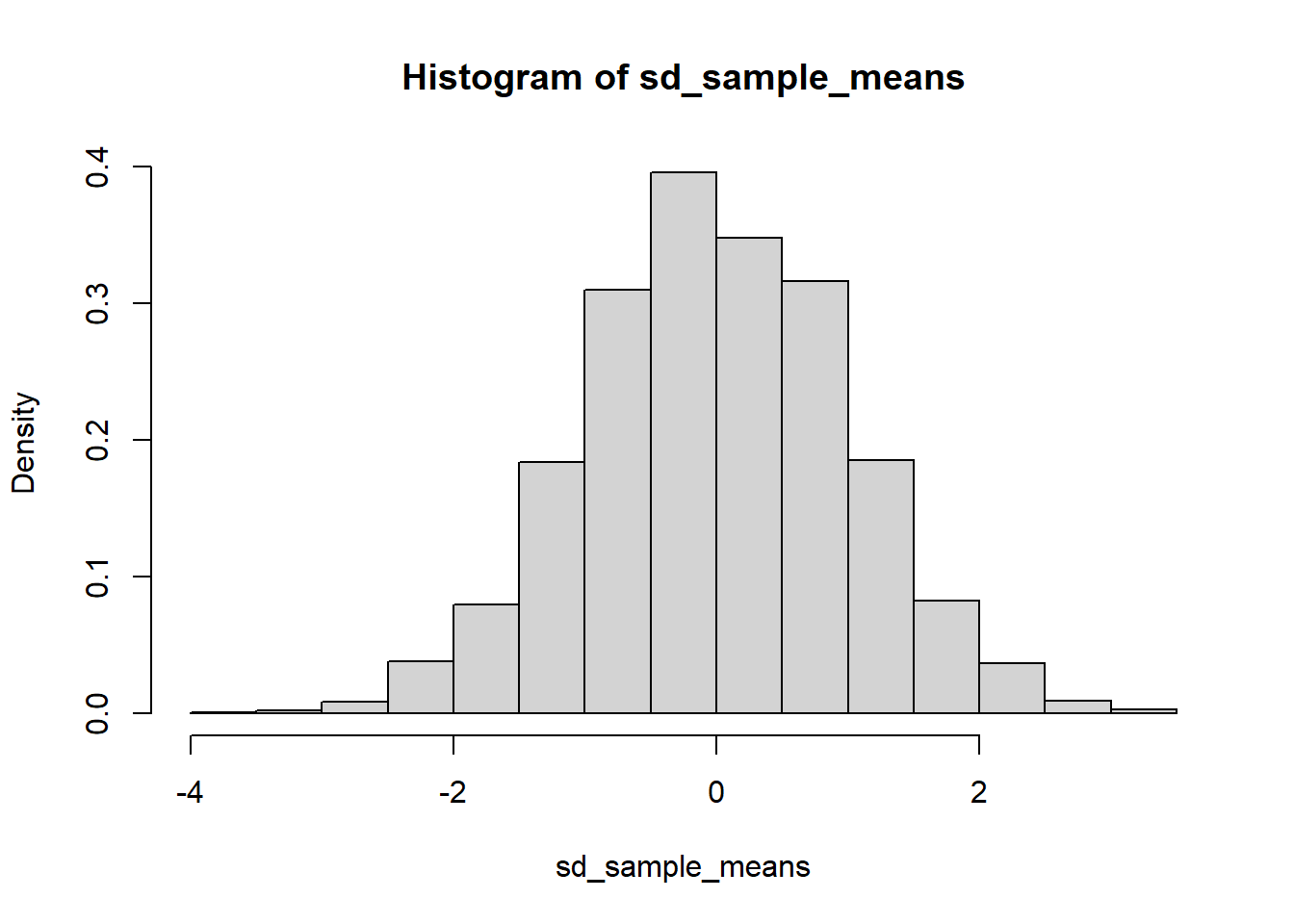
The distribution above is known as the sampling distribution of the sample mean. It characterizes how much the sample means vary from one sample to another due to sampling variability.
O segundo tipo de dados consiste em uma amostra. Em razão da proliferação de pesquisas de opinião pública, muitos de vocês podem assumir que a palavra “amostra” implica uma “amostra aleatória”. Mas este não é o caso. Pesquisadores podem produzir uma amostra por meio da aleatoriedade – isto é, cada membro da população tem uma probabilidade igual de ser selecionado para a amostra. Porém, as amostras podem também ser não aleatórias; quando isso ocorre, as denominamos de amostra de conveniência. (p. 152)
Um evento é resultado de uma observação aleatória. Dois ou mais eventos podem ser chamados de eventos independentes se a realização de um dos eventos não afeta a realização dos demais. Por exemplo, o lançamento de dois dados representa eventos independentes, porque o lançamento do primeiro dado não afeta o resultado do lançamento do segundo. (p. 154)
[…] se (mas somente se!) dois eventos forem independentes, então a probabilidade de esses dois eventos ocorrerem é igual ao produto das chances individuais. Então, se você tem uma moeda não viciada e lança-la três veses – tenha em mente que cada lançamento é um evento independente –, a chance de o resultado dos três lançamentos ser igual a coroa é de \(1/2 \times 1/2 \times 1/2 = 1/8\). (p. 154)
Primeiro, ela é simétrica em torno da sua média, de tal modo que a moda, a mediana e a média são iguais. Segundo, a distribuição normal possui áreas abaixo da curva com distâncias específicas definidas a partir da média. Começando da média e adicionando um desvio-padrão para cada uma das direções, temos uma cobertura de 68% de toda a área abaixo da curva. Adicionando mais um desvio-padrão em cada uma das direções, passamos a ter 95% do total da área. Adicionando um terceiro desvio padrão em cada direção, temos 99% da área total da curva capturada. Essa característica é comumente conhecida como regra do 68-95-99 […]. (p. 156)
Sejamos claros: não estamos dizendo para supor um número infinito de lançamento dos dados, mas que os seiscentos lançamentos sejam repetidos infinitas vezes. Essa é uma distinção crítica. Imaginamos que estamos coletando uma amostra de seiscentos lançamentos, não uma, mas um número infinito de vezes. Podemos chamar essa hipotética distribuição das médias amostrais de distribuição amostral. (p. 158)
Se seguirmos esse procedimento, podemos obter a média das amostras e as expor graficamente. Algumas estariam acima de 3.50, outras abaixo e algumas seriam exatamente 3.5. Porém, é nesse ponto que temos o resultado-chave: a distribuição amostral terá distribuição normal, embora a distribuição de frequência subjacente, claramente, não seja normal.
Esse é o insight do teorema do limite central. Se pudéssemos imaginar um número infinito de amostras aleatórias e plotássemos a média de cada uma dessas amostras aleatórias em um gráfico, essas médias amostrais seriam normalmente distribuídas. Adicionalmente, a média da distribuição amostral seria igual à média da verdadeira população. (p. 159)
O erro-padrão da média é, na prática, o desvio-padrão da distribuição amostral, em que \(n\) é o tamanho da amostra:
\[ \sigma_{\bar{Y}} = \dfrac{s_Y}{\sqrt{n}} \]
Vale notar, inclusive, que aumentar exageradamente o tamanho da amostra não surte tanto efeito no erro-padrão da média amostral. Mais especificamente, segue da fórmula que o erro-padrão diminui proporcionalmente à raiz quadrada do tamanho da amostra. Uma amostra “moderada” (~2.000) nos permite fazer inferências razoáveis.
Suponha um exemplo onde a proporção de indivíduos que apoiam um determinado candidato é de 47% em uma amostra de 1.000 pessoas. A média nesse caso é essa proporção e a variância é \(p(1-p) \approx 0.24\). O desvio padrão é \(\approx 0.5\).
Nosso melhor palpite para a média da população, claro, é 0.47, porque essa é a média da nossa amostra. O erro-padrão da média é dado por \(\sigma_{\bar{Y}} = \frac{0.5}{\sqrt{1000}} = 0.016\), que consiste em uma medida de incerteza sobre a média da população. (p. 161)
Com o erro-padrão, podemos calcular intervalos de confiança adicionando dois erros-padrão (para um intervalo de confiança de 95%) para cada lado a partir do valor da média da amostra.
Vale notar, além disso, que essas propriedades se aplicam apenas aos casos em que estamos utilizando uma amostra completamente aleatória. Esse nem sempre (aliás, quase nunca) é o caso, o que implica a necessidade de integrar técnicas estatísticas mais avançadas para mitigar potenciais vieses da coleta de dados.
Podemos utilizar bootstrap para, usando a própria amostra, nos aproximar do parâmetro populacional. Amostramos várias vezes um subset da amostra coletada, com reposição, e computamos a estatística amostral. Com isso, podemos ter uma ideia de como a média varia se pudéssemos ter várias amostras.
Do ponto de vista frequentista, dizemos que, com 100 amostras e sob um intervalo de confiança de 95%, o parâmetro populacional estará no intervalo em 95% das vezes. Mas, na prática, não conseguimos obter 100 amostras, então isso não é particularmente intuitivo. Então, o bootstrap nos permite produzir uma distribuição amostral da nossa quantidade de interesse.